
Introduction
Infini-gram is an n-gram Language Model developed at the University of Washington. Infini-gram utilizes the largest possible “n” context rather than a fixed context like traditional n-gram models. The unbounded context allows infini-gram to provide more accurate n-gram predictions than traditional models. Infini-gram’s efficient use of a suffix array allows it to have fast expression lookups within large text corpora without using large amounts of space. In our paper, “Ontologies in Language Model Unembedding Matrices”, we used infini-gram to calculate frequencies of terms in comparison to language models’ ontological accuracy of these terms. Infini-gram’s term lookup performance made it a helpful tool in collecting this data but it has many uses outside of expression counting including:
- Counting the number of occurrences of terms of any length within text corpuses or training data.
- Finding the probability of the last token of a given term
- Finding probable next word predictions for a given term (using the greatest possible token context)
- Find samples of all documents containing a given term
How Infini-gram Works
Infini-gram’s largest possible “n” is defined as the longest context string for which there are more than 0 results inside of the corpus.
For example, given the prompt “...conducts research at the Paul G. Allen School of Computer Science and Engineering, University of”, a traditional 5-gram LM will use “Engineering, University of” (5 tokens) as context while the infini-gram model will find the count of the largest possible context string available in the corpus: “research at the Paul G. Allen School of Computer Science and Engineering, University of” for which the only possible continuation of the string is “_Washington”. (As provided by infini-gram’s site here.)
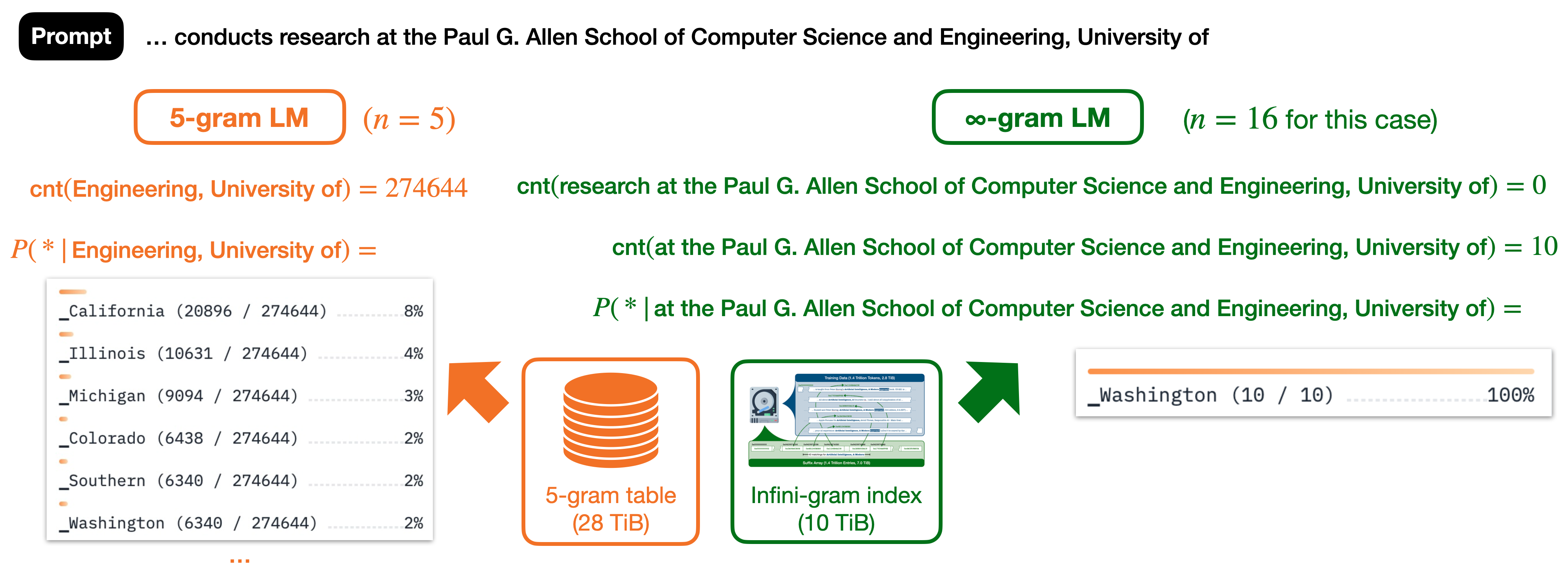
Infini-gram is able to utilize this strategy through its use of a suffix array. In order to create this array, every possible suffix that makes up the targeted corpus is given an integer index based off of their position in the corpus. The indices are lexicographically sorted based on the lexicographical order of the suffixes that they represent and are stored in the suffix array. The lexicographically sorted nature of the suffix arrays allows infini-gram to use binary searches to find and count lexicographically equal occurrences of a given term. Infini-gram achieves O(n) space and (when searching for a term T) \(O(logn* |T|)\) searching rather than traditional O(n*|T|).
How to use Infini-gram
There are two ways to access infini-gram, the infini-gram python package and the infini-gram package. More detailed instructions for the package and API can be found on infini-gram’s website.
Using the Infini-gram API
A more detailed explanation for installation and use can be found on Infini-gram’s API page.
You can access infini-gram through a HTTP POST request with a JSON payload at the endpoint: https://api.infini-gram.io/. This payload should include an ‘index’ (the training data index for the training data you want to collect information about), the ‘query_type’ (for our purposes we used it to find word counts), and the ‘query’ (for this case, we queried the term we wanted to collect a word count for).
Using the Infini-gram Python Package
A more detailed explanation for installation and use can be found on Infini-gram’s python package page.
- Make sure that you have all of infini-gram’s systems requirements
- Infini-gram only works on Linux systems
- The package only supports architectures, x86_64 and i686
- In order to run infini-gram properly, the Python version must be at least version 3.8
- Install infini-gram: pip install infini-gram
- Download your selected pre-built index
- You can also build your own indexes
For example:
{
‘Index’: ‘v4_pileval_llama’,
‘query_type’: ‘count’,
‘query’: ‘programmer’
}You can send these requests through shell or python scripts.
Curl:
curl -X POST -H "Content-Type: application/json" -d '{"index": "v4_rpj_llama_s4", "query_type": "count", "query": "programmer"}' https://api.infini-gram.io/Python:
import requests
payload = {
'index': 'v4_rpj_llama_s4',
'query_type': 'count',
'query': 'programmer',
}
result = requests.post('https://api.infini-gram.io/', json=payload).json()
print(result)After Infini-gram is installed, you can utilize it for any of the uses listed above (details can be found on Infini-gram’s Python Package page)
The infini-gram indices are read-only so you can run infini-gram in parallel on the same index. This can greatly increase the speed of collection of term counts or probabilities if you have access to parallel computing resources.
Use in our project
In our paper, “Ontologies in Language Model Unembedding Matrices” we needed to determine the frequency of terms within training data in order to compare these frequencies to the ontological representations. In order to collect these frequencies, we utilized a powerful tool: infini-gram. Infini-gram allowed us to collect term frequencies of ontology terms within the llama(specific version) corpus. We then analyzed these terms by comparing how their frequency in the corpus affected their ontology scores in order to determine the connections between these factors. Through our work with infini-gram we have discovered its usefulness and the many uses it has in studying pre-training data or large corpuses.
An example package usage from our project:
from infini_gram.engine import InfiniGramEngine
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-hf", add_bos_token=False, add_eos_token=False)
engine = InfiniGramEngine(index_dir='index/v4_pileval_llama', eos_token_id=tokenizer.eos_token_id)In our project, we needed to calculate approximately 2.9 million frequencies over 115 OBO Foundry files. To collect these frequencies, we utilized both Infini-gram’s API and Python Package. The Python Package was able to calculate an average of 1.1714 frequency calculations per second. Calculating these frequencies sequentially would have taken approximately 945 hours.
In order to increase the speed of our data collection, we used Joblib’s parallelization to run these infini-gram frequency count calculations over multiple OBO-Foundry data sets in parallel with 40 cors running simultaneously. Due to this, we were able to collect our frequencies much faster. We also used chunking to improve speeds to save progress in the event of errors or other issues.
To learn more about our project or to review our usage of infini-gram, see our Ontology Topology research project or project github repository. Within the github repository in folder “llm_ontology” you will find our frequency collection python script: frequencies.py which you as well as our collected frequencies within the folder: “/data/term_frequencies/”.
You can also collect further frequencies within the terminal by running the file from the terminal with “python frequencies.py
Use in our project
During our use of infini-gram in our project, we have come up with some best practices:
- While infini-gram only works for Python versions later than 3.8, we also experienced some python interpreter issues with Python 3.13. Python 3.12.8 provided the most stable experience but any version between 3.8-3.12.8 should provide the best results.
- In order to prevent indexing issues, double check your indexing paths before you call them and make sure that you have enough space to download large training data indexes.
- Infini-gram enforces unspecified rate limits that prevent excessive API calls. In order to reduce the effects of these rate limits, you can include retries on errors into your code in case an error occurs. Also, you can utilize timeouts to prevent exceeding the infini-gram rate limits.
- During large scale data collection, you can use chunking like we did in our project to reduce time consuming data movement
Conclusion
Infini-gram is a very useful tool in data collection, language models, and training data research. Its creative use of suffix arrays have allowed it to revolutionize n-gram models and greatly improve predictions and expression searches. If you are interested in infini-gram and want to learn more about it, please read the infini-gram paper here. Infini-gram has helped us in our work on Ontology Topologies and we hope it can help you too.